In the site Bad Mathematics, Marty and Christian R have recently been discussing the relation between History and Mathematics. Their discussion was wide ranging but the pointy end of it seems to be whether maths teaching benefits from presenting a topic in its historical context. Such an approach may offer a natural introduction, motivating the topic and leading directly to applications. The alternative is to offer the modern pared-down version, direct and logical. At the same time I was preparing this post which relates my personal experience of a lecture that offers evidence for both sides. The topic was Lagrange multipliers, so let me start with a quick introduction for newbies.
Suppose we wish to find the minimum value for the function 





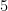
The Lagrange method instead considers a combination of the objective and the constraint, 








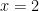
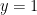

Why make things harder in this way? Well in many cases the constraint equation cannot be solved to get one variable in terms of the other. For example, what if the constraint is 
So how did my lecturer approach this? She started by defining “infinitesimals”. Yes! Back in the 60s, optimization research papers and textbooks were still using those critters that are infinitely small but not zero. But she must have realized they were problematic because she had a new definition. Instead of defining 



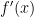




My lecturer then introduced the problem of optimizing 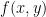



Over the next few decades I would occasionally recall these Lagrange things, but never found the time to solve the mystery of their origin. Until 1999 that is, when I accepted a job in a research team at Monash, implementing optimization algorithms in a suite of software. Before starting I decided to resolve the mystery, just for self respect.
Lagrange and I shared the same handicap. We both learned calculus as a tool for modelling dynamics. We both missed out on the modern approach that divorces subjects from their roots. In Lagrange’s day the hot topic was the use of potential theory for dynamics. For example if a particle is moving under a scalar potential 

![, \frac{\partial f}{\partial y}] = [-2x, -2y]](https://s0.wp.com/latex.php?latex=%2C+%5Cfrac%7B%5Cpartial+f%7D%7B%5Cpartial+y%7D%5D+%3D+%5B-2x%2C+-2y%5D&bg=ffffff&fg=000&s=0&c=20201002)

![[-2,-2]](https://s0.wp.com/latex.php?latex=%5B-2%2C-2%5D&bg=ffffff&fg=000&s=0&c=20201002)
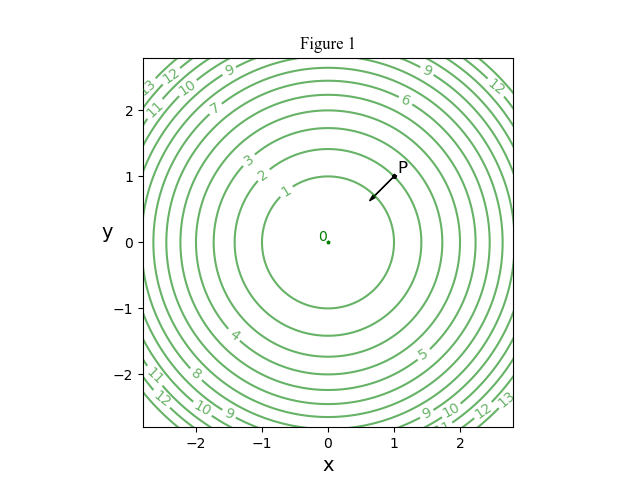
Now let’s introduce the constraint 







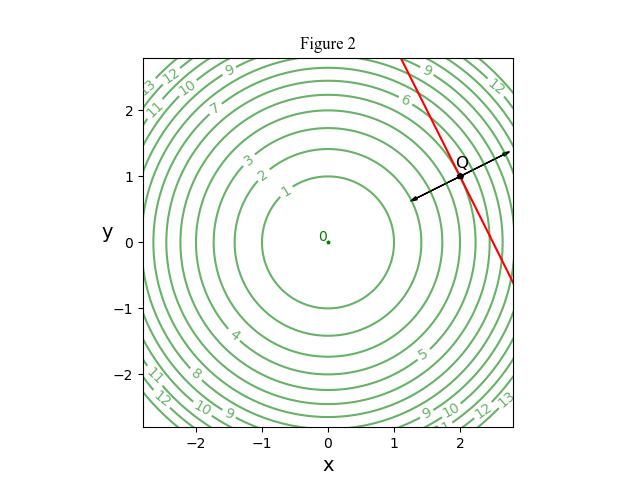
Time for a literature search. Damn. Wikipedia gives almost an identical derivation to mine. So I pull down my 70s texts on optimization. None use this approach. One takes the lecturer’s route of plucking the Lagrange multiplier from nowhere. The others find different algebraic routes, none obvious. My conclusion is that Lagrange almost certainly used the dynamics argument but this was neglected when calculus was cleansed of physics.
How does this answer the issue of the historical approach to teaching mathematics?
- Treating optimization as an exercise in Physics makes the derivation intuitive and easy. The historical approach is good.
- Sticking to the traditional use of infinitesimals just muddies the issue for a modern reader. The historical approach is bad.
Furthermore
for those interested in the optimization theory …
A: What would it mean if we found 
B: We have been finding stationary points. Usually the nature of the optimization problem fingers the point as giving either a minimum or a maximum. If in doubt then one may resort to the Hessian matrix.
C: Suppose that we optimize 






D: If a constraint is an inequality constraint, rather than an equality one, then if that constraint is active, the corresponding force vector has a specified sense. The Lagrange multiplier for that constraint will be either strictly positive or strictly negative, depending on the allowed direction of the inequality. We are on the road to Kurush-Kuhn-Tucker theory.
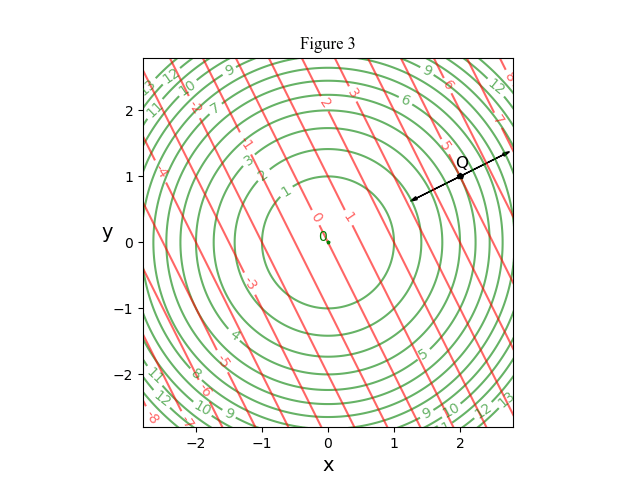
E: Returning to 2 dimensions and 1 constraint, an engineer may be interested in the trade-off between the constraint and the minimum 


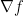







F: Looking again at Figure 3, suppose that we swap the roles of the families of contours. Now the green contours are the constraints and the red ones represent the function to be optimized. This time we obtain 



G: Here is a classic pair of dual optimization problems. A nice exercise is to draw the relevant level curves.
A farmer is fencing a rectangular paddock on 3 sides. (The other side uses an existing fence.)
- Suppose the new fence has length 800 m. Find the dimensions of the paddock that has maximum area.
- Suppose instead that the enclosed area needs to be 80,000 m2. Find the dimensions of the paddock that will use minimum fence length.
H: The physical interpretation of Figure 3 is a gift that keeps giving. In that figure interpret the two contour families as competing objectives. This leads to a new direct search algorithm for bi-objective optimization.
 using what the ancient Greeks “must” have done before settling on the method of exhaustion. This just broke the area of a disc into infinitely many circles. I don’t think she was damaged by the lesson, rather the opposite 😉
using what the ancient Greeks “must” have done before settling on the method of exhaustion. This just broke the area of a disc into infinitely many circles. I don’t think she was damaged by the lesson, rather the opposite 😉 . If we cut and straighten them, then lay them together they make a right triangle with length
. If we cut and straighten them, then lay them together they make a right triangle with length  , giving an area
, giving an area  . She followed it all; I took pains to explain that her teachers might not accept such an argument. I guess the Banach-Tarski paradox makes the approach even more doubtful.
. She followed it all; I took pains to explain that her teachers might not accept such an argument. I guess the Banach-Tarski paradox makes the approach even more doubtful.
Leave a reply to tom Cancel reply